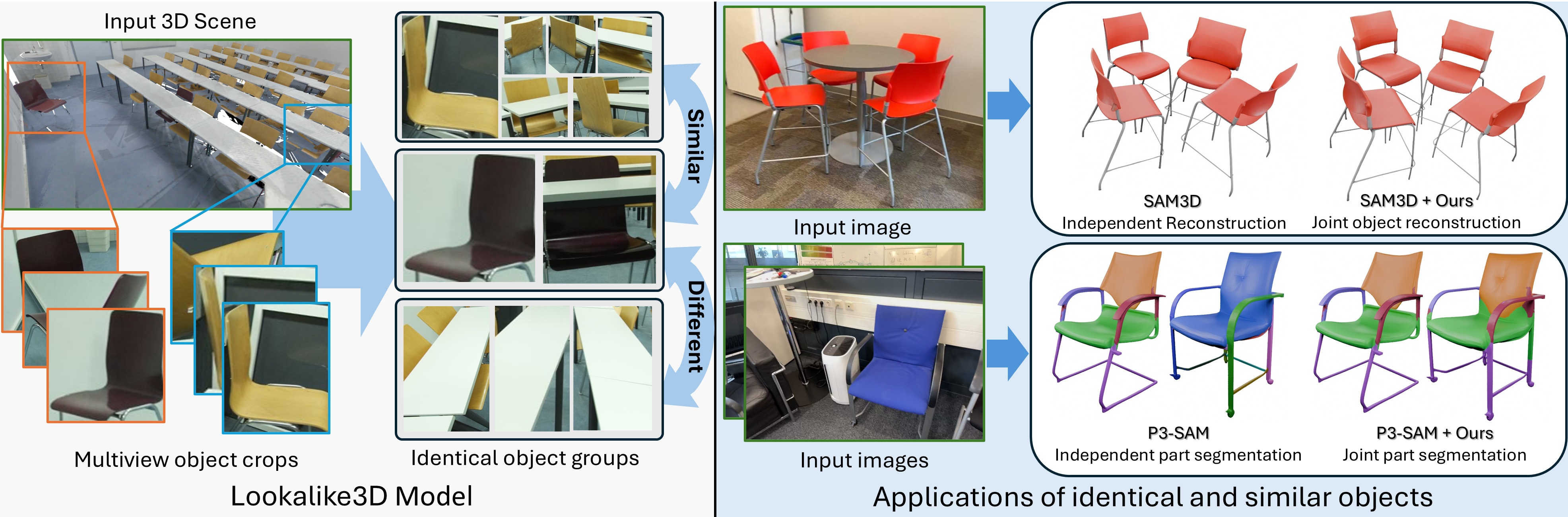
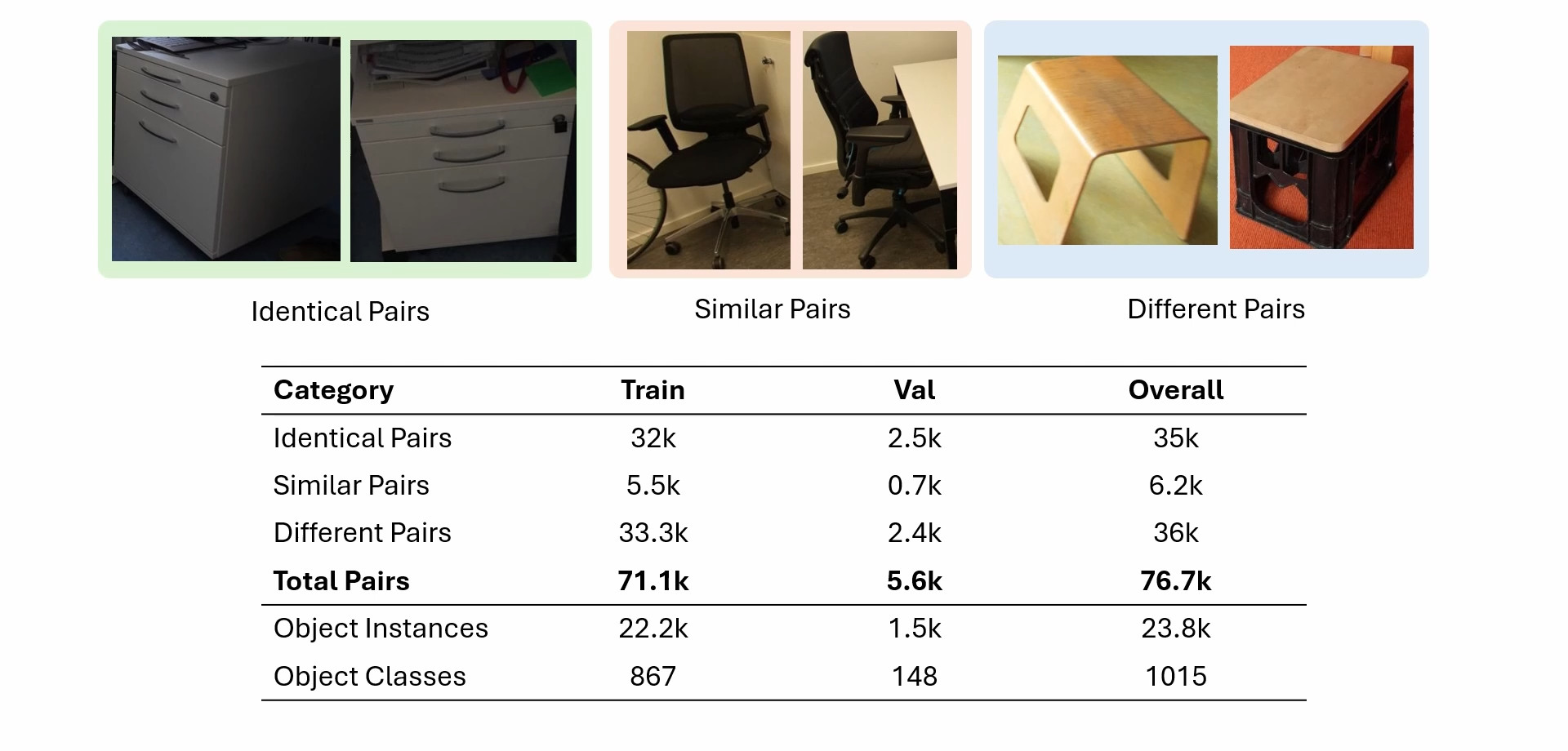
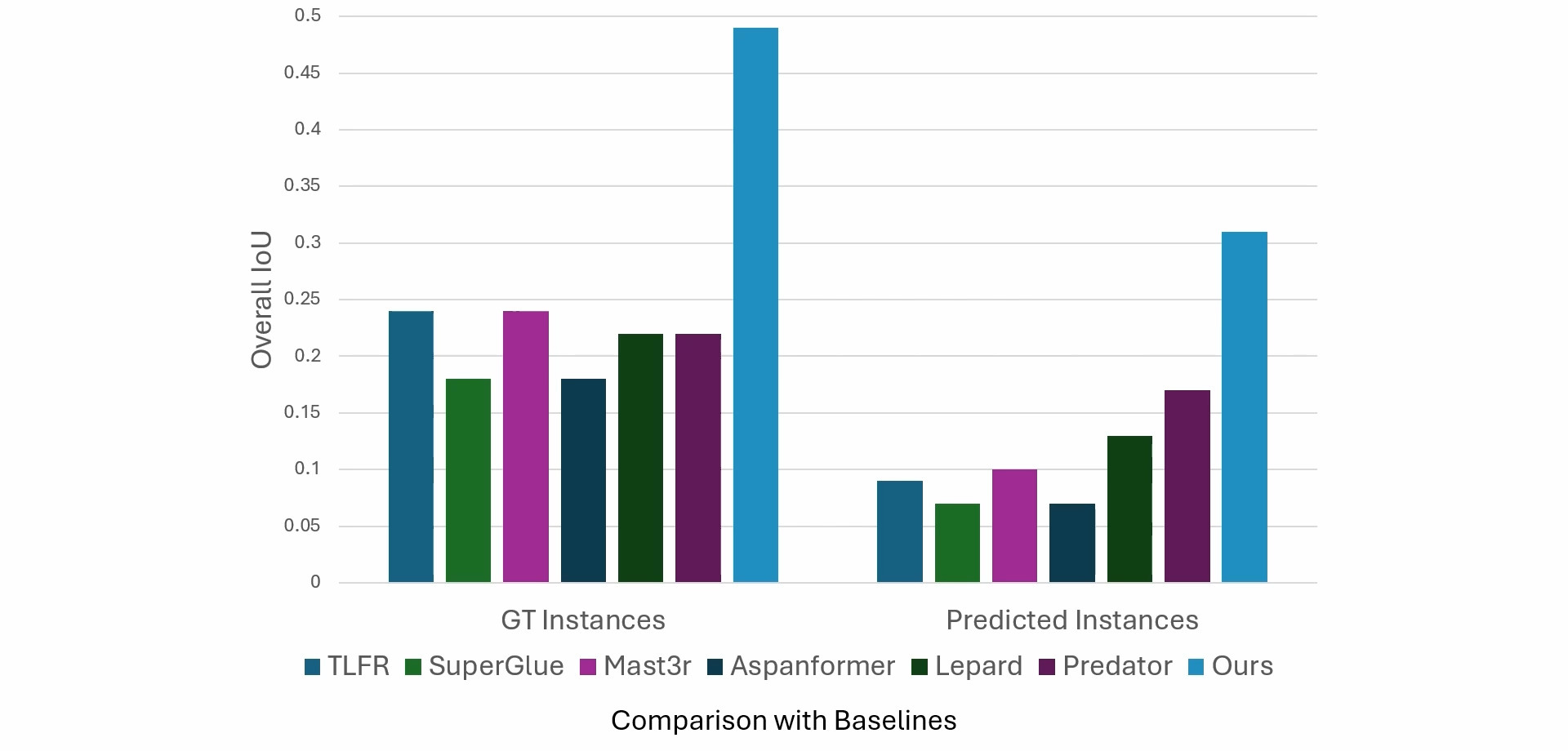
3D object understanding and generation methods produce impressive results, yet they often overlook a pervasive source of infor- mation in real-world scenes: repeated objects. We introduce the task of lookalike object detection in 3D scenes, which leverages repeated and complementary cues from identical and near-identical object pairs. Given a 3D scene, the task is to classify pairs of objects as identical, similar or different using multiview images as input. To address this, we present Lookalike3D, a multiview image transformer that effectively distinguishes such object pairs by harnessing strong semantic priors from large image foundation models. To support this task, we collected the 3DTwins dataset, containing 76k manually annotated identical, similar and different pairs of objects based on ScanNet++, and show an improvement of 104% IoU over baselines. We demonstrate how our method improves downstream tasks such as enabling joint 3D object reconstruction and part co-segmentation, turning repeated and lookalike objects into a powerful cue for consistent, high-quality 3D perception.
@misc{yeshwanth2026lookalike3d,
title={Lookalike3D: Seeing Double in 3D},
author={Chandan Yeshwanth and Angela Dai},
year={2026},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={},
}